
アクションの概要説明
今回は、「PDFからテキストを抽出」を説明していきます。このアクションはPDFファイルからテキストデータを取り出すことができます。
「PDFからテキストを抽出」をする場合、下記のようにアクションを開いてみましょう。
アクションの位置

アクションの展開はアクション名をダブルクリックするか、フロー画面へのドラッグで可能です。
アクション設定画面
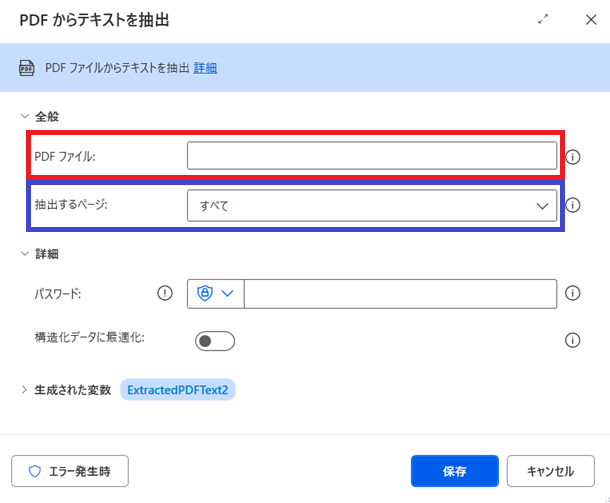
取得したいPDFのファイルのパスを(赤枠)に入力します。直接ファイルパスを記載するか、変数でも指定できます。
抽出するページの設定方法
抽出するページは、以下の項目があり、プルダウンで選択が可能です。
- すべて
- 単一
- 範囲
それぞれの機能を以下で説明します。
すべて
ファイル内、全てのテキストデータが取得できます。
単一
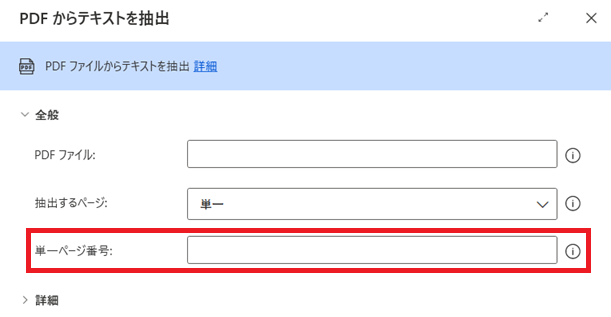
単一を選択すると、以下の赤枠が設定できるようになります。単一ページ番号の欄にデータを取得するPDFファイルの頁を数値で入力することで、指定した頁のテキストデータが取得できます。
範囲
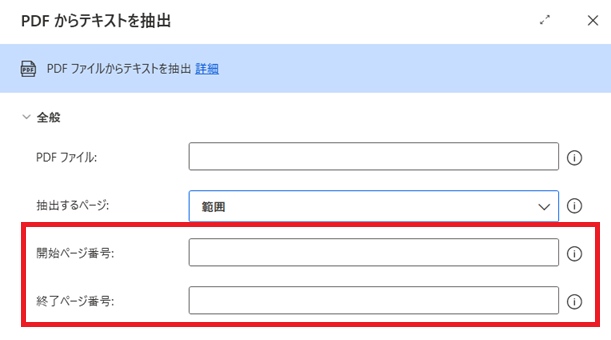
範囲を選択すると、以下の赤枠が設定できるようになります。開始ページ番号の欄にデータを取得する最初の頁を、終了ページ番号の欄にデータを取得する最後の頁を数値入力することで、指定した範囲のテキストデータが取得できます。
詳細設定項目
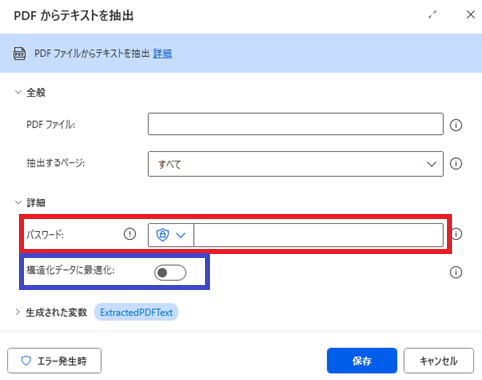
詳細項目には、「パスワード」「構造化データに最適化」が設定できます。これら設定を解説します。
パスワード
データを取得したいPDFファイルにパスワードが設定されている場合、ファイルを開く際に赤枠にパスワードを入力しておくことで、PADでファイルを開くことができます。
もしPDFファイルにパスワードが設定されていない場合、空欄のままとしてください。
構造化データに最適化
「構造化データに最適化」のスイッチの効果について解説します。
構造化データに最適化を有効にする場合、青枠のスイッチをONします。
(初期値はOFFになっています)
以下のPDFファイルからデータ取得した場合、「構造化データの最適化」が、ON・OFFそれぞれの結果を確認してみましょう。
用途によって、メリット、デメリットありますのでお好みに応じて ご使用ください。
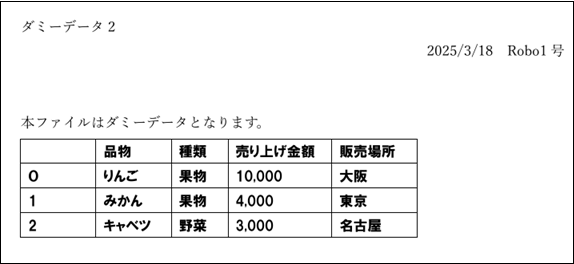
構造化データOFFの場合
データが左詰めで代入されます。
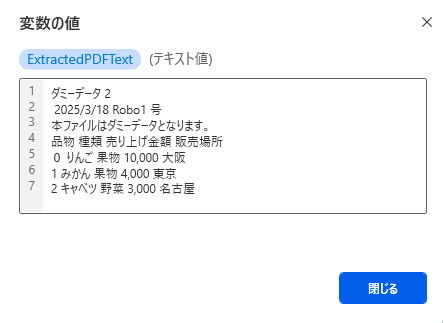
構造化データONの場合
PDFの元レイアウトにできるだけ準じた配置のデータとなります。
(位置合わせは空白が入っています)
使用上の注意事項
PDFファイルに埋め込まれている、テキストデータしかデータ取得ができません。OCRによるテキスト抽出機能はありませんので、ただのスキャンデータからの読み出しはできません。
Robo1号の感想
近年、情報の多くはPDFファイルで提供されるので、業務の中でPDFからデータを取得する機会は増えているね。いままでは手動でPDFから転記していたけど、このアクションで効率的にPDFデータを活用しようと思っているよ!!

